ZajiĆĄtÄnĂ spolehlivosti BMS
ModernĂ budovy umoĆŸĆujĂ sjednotit sledovĂĄnĂ a ovlĂĄdĂĄnĂ rĆŻznĂœch automatizaÄnĂch a elektronickĂœch systĂ©mĆŻ do jednoho prostĆedĂ, nazĂœvanĂ©ho BMS (Building Management System). ZatĂmco v mnohĂœch instalacĂch BMS hraje roli doplĆku, kterĂœ zejmĂ©na zvyĆĄuje pohodlĂ prĂĄce, od urÄitĂ© velikosti systĂ©mu se BMS stĂĄvĂĄ nepostradatelnou souÄĂĄstĂ provozu budovy, kterĂĄ jednak zajiĆĄĆ„uje veĆĄkerou komunikaci mezi uĆŸivateli a zaĆĂzenĂmi, a jednak umoĆŸĆuje vĂœraznÄ snĂĆŸit nĂĄklady pĆi dalĆĄĂm rozĆĄiĆovĂĄnĂ. V takovĂ©m pĆĂpadÄ se spolehlivost a dostupnost systĂ©mu BMS stĂĄvĂĄ kritickou pro zajiĆĄtÄnĂ bezproblĂ©movĂ©ho fungovĂĄnĂ organizace. V tomto ÄlĂĄnku jsou pĆedstaveny jak technickĂ©, tak metodickĂ© aprocesnĂ aspekty zajiĆĄtÄnĂ spolehlivosti systĂ©mu BMS, zaloĆŸenĂ© na zkuĆĄenostech z dlouhodobĂ©ho provozovĂĄnĂ BMS na MasarykovÄ univerzitÄ. DodrĆŸovĂĄnĂ pĆedstavenĂœch zĂĄsad umoĆŸĆuje pouĆŸĂvat BMS jako primĂĄrnĂ prostĆedĂ pro ovlĂĄdĂĄnĂ technologiĂ budov.
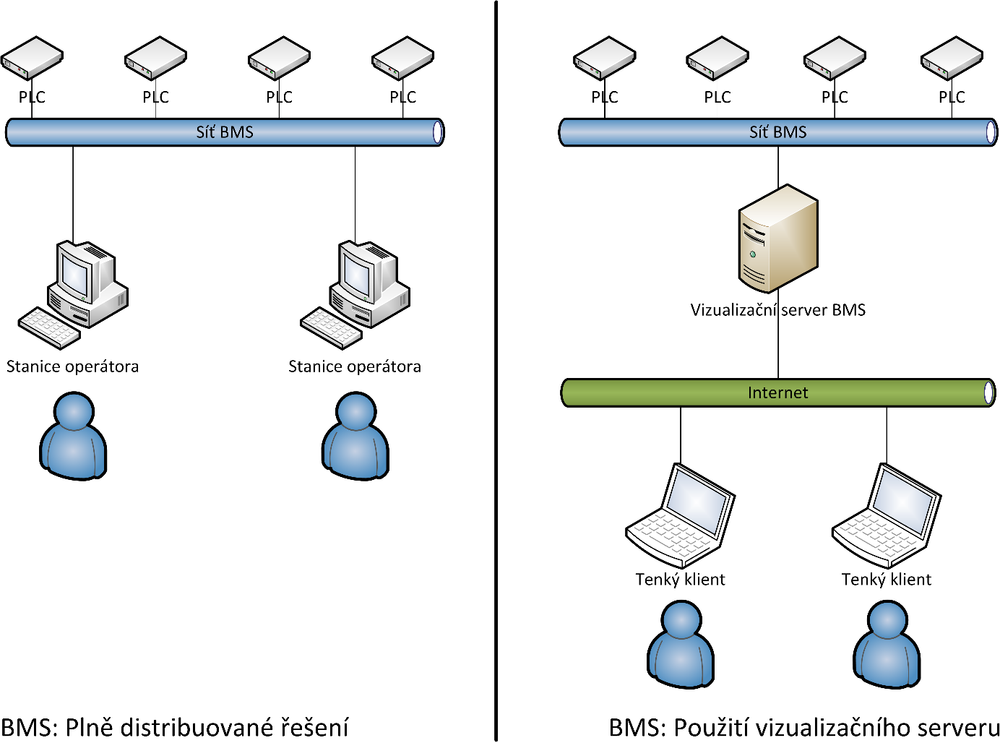
ObrĂĄzek 1: VyuĆŸitĂ vizualizaÄnĂho serveru
ModernĂ stavby jsou obvykle vybaveny technologiemi automatizace budov, z nichĆŸ zĆejmÄ nejvĂœznamnÄjĆĄĂ souÄĂĄstĂ je systĂ©m mÄĆenĂ a regulace nebo monitoring spotĆeby energiĂ. V budovĂĄch se nachĂĄzejĂ i dalĆĄĂ elektronickĂ© systĂ©my jako napĆĂklad elektronickĂĄ poĆŸĂĄrnĂ signalizace, elektronickĂĄ kontrola vstupu nebo zabezpeÄovacĂ systĂ©m. VĆĄechny tyto systĂ©my mohou bĂœt integrovĂĄny do takzvanĂ©ho BMS (Building Management System), coĆŸ je prostĆedĂ, kterĂ© poskytuje jednak infrastrukturu pro komunikaci mezi systĂ©my a zĂĄroveĆ takĂ© zajiĆĄĆ„uje funkci rĆŻznĂœch dalĆĄĂch sluĆŸeb, kterĂ© usnadĆujĂ provoz budovy. Mezi tyto sluĆŸby patĆĂ zejmĂ©na vizualizaÄnĂ rozhranĂ, pomocĂ kterĂ©ho lze technologie budov ovlĂĄdat. VizualizaÄnĂ rozhranĂ bĂœvĂĄ Äasto realizovĂĄno formou serveru, ke kterĂ©mu se pĆipojujĂ tzv. tencĂ klienti, takĆŸe kaĆŸdĂœ uĆŸivatel nemusĂ mĂt k dispozici plnohodnotnou aplikaci pro komunikaci se systĂ©mem a navĂc nemusĂ mĂt k dispozici ani pĆĂmĂ© pĆipojenĂ k zaĆĂzenĂm, se kterĂœmi pracuje (viz ObrĂĄzek 1: VyuĆŸitĂ vizualizaÄnĂho serveru). DalĆĄĂ poskytovanou sluĆŸbou jsou zejmĂ©na alarmovĂ© a notifikaÄnĂ zprĂĄvy, kterĂ© jsou buÄ zobrazovĂĄny v prostĆedĂ vizualizaÄnĂ aplikace, nebo pĆedĂĄvĂĄny dĂĄle napĆ. pomocĂ SMS brĂĄny. PoslednĂ obvyklou poskytovanou sluĆŸbou je archivnĂ server, coĆŸ je databĂĄze, kterĂĄ umoĆŸĆuje uklĂĄdat provoznĂ data pro pozdÄjĆĄĂ analĂœzu.
BMS jednak zvyĆĄujĂ uĆŸivatelskĂ© pohodlĂ a zvyĆĄujĂ efektivitu prĂĄce pĆi zajiĆĄĆ„ovĂĄnĂ provozu budov, zĂĄroveĆ ale v rozsĂĄhlĂœch systĂ©mech mohou sniĆŸovat nĂĄklady na softwarovĂ© a hardwarovĂ© vybavenĂ. Jako pĆĂklad uveÄme situaci, kdy je stĂĄvajĂcĂ BMS rozĆĄiĆovĂĄn o novĂĄ zaĆĂzenĂ (napĆ. byla postavena novĂĄ budova). V situaci, kdy by novĂĄ budova byla provozovĂĄna autonomnÄ, bylo by kromÄ jinĂ©ho poĆĂdit i programovou licenci pro stanoviĆĄtÄ operĂĄtora, ze kterĂ©ho bude probĂhat obsluha systĂ©mu, pĆĂpadnÄ i pro archivaÄnĂ server. Pokud vĆĄak pĆipojujeme novou budovu k existujĂcĂmu BMS, kde je jiĆŸ k dispozici vizualizaÄnĂ a archivaÄnĂ (aĆ„ uĆŸ ve formÄ webovĂ© aplikace, nebo serveru, ke kterĂ©mu se lze pĆipojit pomocĂ tenkĂœch klientĆŻ), nenĂ tato investice nutnĂĄ. StaÄĂ novĂĄ zaĆĂzenĂ pĆipojit do stĂĄvajĂcĂ sĂtÄ a rozĆĄĂĆit uĆŸivatelskĂ© rozhranĂ o vizualizaci novÄ pĆidĂĄvanĂœch zaĆĂzenĂ a zmÄnit konfiguraci archivaÄnĂho serveru.
V rozsĂĄhlĂœch systĂ©mech s velkĂœm poÄtem zaĆĂzenĂ, velkĂœm poÄtem uĆŸivatelĆŻ a zejmĂ©na vÄtĆĄĂ geografickou rozlohou vĆĄak jiĆŸ BMS pĆestĂĄvĂĄ bĂœt pouhou „nadstavbou“ zvyĆĄujĂcĂ pohodlĂ, ale stĂĄvĂĄ se nezbytnĂœm pro zajiĆĄtÄnĂ provozu. VelkĂ© mnoĆŸstvĂ prvkĆŻ systĂ©mu a takĂ© nemoĆŸnost rychlĂ© fyzickĂ© kontroly (napĆ. kvĆŻli velkĂ© dochĂĄzkovĂ© vzdĂĄlenosti) znamenĂĄ, ĆŸe uĆŸivatelĂ© jsou odkĂĄzĂĄni na automatickĂ© notifikace o alarmovĂœch stavech z BMS a takĂ© ovlĂĄdĂĄnĂ systĂ©mu je provĂĄdÄno prakticky vĂœhradnÄ pĆes vizualizaÄnĂ server. Ve chvĂli, kdy se uĆŸivatelĂ© zaÄnou na tento systĂ©m spolĂ©hat, je tĆeba zajistit jeho nepĆetrĆŸitou funkÄnost, protoĆŸe vĂœpadky mohou mĂt vĂĄĆŸnĂ© ekonomickĂ© i technickĂ© dopady.
Tento ÄlĂĄnek se vÄnuje rĆŻznĂœm aspektĆŻm provozu BMS, kterĂ© majĂ vztah k zajiĆĄtÄnĂ vysokĂ© dostupnosti a spolehlivosti. Tyto oblasti vychĂĄzĂ ze zkuĆĄenostĂ s provozovĂĄnĂm BMS Masarykovy univerzity (dĂĄle MU), jehoĆŸ podrobnÄjĆĄĂ popis lze nalĂ©zt v [http://www.tzb-info.cz/facility-management/11078-bms-na-masarykove-univerzite]. JednĂĄ se zejmĂ©na o:
- RedundantnĂ infrastrukturu;
- Dohledové systémy;
- ProcesnĂ postupy pĆi reakci na zĂĄvadu a znalostnĂ databĂĄze;
- SprĂĄvu konfiguracĂ;
- Sklad nĂĄhradnĂch dĂlĆŻ;
- SprĂĄvu uĆŸivatelskĂœch oprĂĄvnÄnĂ a auditing (sledovĂĄnĂ uĆŸivatelskĂœch operacĂ);
- ProcesnĂ postupy pĆi ĂșpravĂĄch systĂ©mu (testovĂĄnĂ novĂœch zaĆĂzenĂ, rozĆĄiĆovĂĄnĂ systĂ©mu, Ășpravy konfigurace).
SprĂĄva BMS je v mnohĂ©m podobnĂĄ sprĂĄvÄ „standardnĂ“ poÄĂtaÄovĂ© sĂtÄ, kde jsou tyto oblasti dobĆe metodicky (napĆ. ISO model FCAPS – Fail, Configuration, Auditing, Performance and Security Management) i technicky zvlĂĄdnutĂ© (protokol SNMP – Simple Network Management Protocol). ZĂĄroveĆ existujĂcĂ komerÄnĂ nĂĄstroje, kterĂ© komplexnÄ pokrĂœvajĂ sprĂĄvu sĂtĂ. Pro oblast automatizace budov vĆĄak takovĂĄto podpora vesmÄs chybĂ, zĆejmÄ zejmĂ©na dĂky velkĂ©mu mnoĆŸstvĂ pouĆŸĂvanĂœch protokolĆŻ (BACnet, LonWorks, MODBUS, M-BUS,…).
V dalĆĄĂch ÄĂĄstech ÄlĂĄnku jsou postupnÄ popsĂĄny jednotlivĂ© oblastnĂ zajiĆĄĆ„ovĂĄnĂ spolehlivosti BMS, jejich vĂœznam, problĂ©my, se kterĂœmi se setkĂĄvĂĄme, a moĆŸnĂĄ ĆeĆĄenĂ.
RedundantnĂ infrastruktura
RedundantnĂ infrastruktura zajiĆĄĆ„uje bÄh klĂÄovĂœch souÄĂĄstĂ systĂ©mu i v pĆĂpadÄ, ĆŸe dojde k selhĂĄnĂ jednĂ© komponenty. Koncept redundance klĂÄovĂœch prvkĆŻ je bÄĆŸnÄ pouĆŸĂvĂĄn ve standardnĂm ICT, i kdyĆŸ samozĆejmÄ obnĂĄĆĄĂ zvĂœĆĄenĂ© nĂĄklady. Jeho nasazenĂ pro oblast automatizace budov je relativnÄ bezproblĂ©movĂ© dĂky tomu, ĆŸe komunikace v BMS na nejvyĆĄĆĄĂ Ășrovni (napĆ. mezi stanicemi operĂĄtorĆŻ, vizualizaÄnĂm a archivnĂm serverem a integraÄnĂmi regulĂĄtory) zapouzdĆenĂœch do standardnĂch sĂĆ„ovĂœch protokolĆŻ jako Ethernet nebo TCP/IP.
V zĂĄsadÄ mĂĄme k dispozici nÄkolik technik pro zajiĆĄtÄnĂ redundance:
- NĂĄsobenĂ hardwarovĂœch komponent – Tento postup nalezne vyuĆŸitĂ zejmĂ©na u serverĆŻ a dalĆĄĂch komplexnĂch zaĆĂzenĂ. JednĂĄ se zejmĂ©na o vyuĆŸĂvĂĄnĂ zrcadlenĂ pevnĂœch diskĆŻ v poÄĂtaÄi a vybavenĂ strojĆŻ redundantnĂmi napĂĄjecĂmi zdroji (a jejich zapojenĂ na nezĂĄvislĂ© napĂĄjecĂ okruhy).
- NĂĄsobnĂ© sĂĆ„ovĂ© cesty – AktivnĂ prvky poÄĂtaÄovĂ© sĂtÄ jsou zapojeny a nakonfigurovĂĄny takovĂœm zpĆŻsobem, ĆŸe jsou minimĂĄlnÄ zdvojeny vĂœznamnĂ© komunikaÄnĂ kanĂĄly – napĆĂklad spojenĂ mezi budovami a centrĂĄlnĂm uzlem BMS, zejmĂ©na pomocĂ technologie Spanning Tree na Ășrovni pĆepĂnaÄĆŻ protokolu Ethernet a pomocĂ vhodnÄ nastavenĂœch smÄrovacĂch tabulek na Ășrovni protokolu IP.
- RozloĆŸenĂ zĂĄtÄĆŸe – Tuto techniku lze vyuĆŸĂt napĆ. pro aplikaÄnĂ servery. NÄkolik vzĂĄjemnÄ plnÄ zastupitelnĂœch uzlĆŻ lze nakonfigurovat tak, aby pĆed uĆŸivatelem vystupovaly pod jednou adresou (tzv. loadbalancing cluster). PrimĂĄrnĂm ĂșÄelem tĂ©to technologie je rozloĆŸit zĂĄtÄĆŸ, zpĆŻsobenou velkĂœm poÄtem pĆipojenĂœch uĆŸivatelĆŻ, na vĂce samostatnĂœch serverĆŻ. Z hlediska zajiĆĄtÄnĂ dostupnosti mĂĄ vĆĄak takĂ© svĆŻj vĂœznam. V pĆĂpadÄ vĂœpadku jednoho z uzlĆŻ dojde k jeho vyĆazenĂ z clusteru a takĂ© k pĆesmÄrovĂĄnĂ uĆŸivatelĆŻ na nÄkterĂœ z funkÄnĂch serverĆŻ. V prostĆedĂ Microsoft Windows je tato technologie pojmenovĂĄna Network Load Balancing (NLB) a je standardnĂ souÄĂĄstĂ serverovĂ©ho operaÄnĂho systĂ©mu.
- Virtualizace – Virtualizace serveru umoĆŸĆuje jeho snadnĂœ pĆesun na jinĂ©ho fyzickĂ©ho hostitele v pĆĂpadÄ vĂœpadku fyzickĂ©ho zaĆĂzenĂ, na kterĂ©m virtualizovanĂœ server bÄĆŸel. Virtualizace umoĆŸĆuje takĂ© snadnĂ© zĂĄlohovĂĄnĂ stavu serveru. ObzvlĂĄĆĄtÄ vĂœhodnĂ© je provozovat virtualizaci ve spojenĂ s technologiĂ „Failover clustering“ (viz dĂĄle).
- Failover clustering – Na rozdĂl odreĆŸimu rozloĆŸenĂ zĂĄtÄĆŸe tato technologie sice takĂ© vyuĆŸĂvĂĄ vĂce uzlĆŻ, vystupujĂcĂch pod jednou adresou, v danĂœ okamĆŸik je vĆĄak aktivnĂ pouze jeden z nich. OstatnĂ jsou pĆipraveny jako tzv. „horkĂĄ zĂĄloha“ v pĆĂpadÄ vĂœpadku aktivnĂho uzlu plnÄ pĆevzĂt jeho roli. V BMS Masarykovy univerzity je tato technologie vyuĆŸĂvĂĄna ve dvou pĆĂpadech. PrvnĂm je Failover cluster nad fyzickĂœmi poÄĂtaÄi, kterĂ© slouĆŸĂ jako hostitelĂ© pro virtualizovanĂ© servery, kterĂ© automaticky migrujĂ mezi tÄmito dvÄma hostiteli (Hyper-V Failover cluster). V druhĂ©m pĆĂpadÄ je vytvoĆen Failover cluster nad databĂĄzovĂœmi servery (SQL Failover Cluster). Failover clustering vyĆŸaduje investici do samostatnĂ©ho diskovĂ©ho pole, protoĆŸe pro sprĂĄvnou funkci tĂ©to technologie je nutnĂ© mĂt k dispozici nezĂĄvislĂ© sdĂlenĂ© ĂșloĆŸiĆĄtÄ.
Ze zkuĆĄenostĂ z provozu BMS MU plyne, ĆŸe technologie rozloĆŸenĂ zĂĄtÄĆŸe je vhodnĂĄ pro vizualizaÄnĂ servery, protoĆŸe nezpĆŻsobuje zvĂœĆĄenou komunikaci v BMS (objem komunikace se vĂœraznÄ nemÄnĂ v zĂĄvislosti na tom, jestli uĆŸivatelĂ© vĆĄichni vyuĆŸĂvajĂ jeden server, nebo jsou rozprostĆeni na vĂce uzlech). Z vĂœkonovĂœch dĆŻvodĆŻ nejsou server BMS virtualizovĂĄny. Virtualizace spolu s technologiĂ Failover Clustering je naopak vhodnĂĄ pro archivnĂ server. VirtualizovĂĄna je jeho aplikaÄnĂ ÄĂĄst, tzn. program, kterĂœ komunikuje se zaĆĂzenĂmi v BMS, zpracovĂĄvĂĄ data a odesĂlĂĄ je do databĂĄze. SamotnĂ© databĂĄzovĂ© ĂșloĆŸiĆĄtÄ je oddÄlenĂ© a vyuĆŸĂvĂĄ MS SQL Failover Clustering. RozloĆŸenĂ zĂĄtÄĆŸe pro archivnĂ server nenĂ vhodnĂ©, protoĆŸe v takovĂ©m pĆĂpadÄ by musely existovat dva archivnĂ servery se stejnou konfiguracĂ, takĆŸe by vĆĄechna data musela bĂœt ze zaĆĂzenĂ stahovĂĄna a potĂ© uklĂĄdĂĄna dvakrĂĄt.
Naopak je nemoĆŸnĂ© v redundantnĂm reĆŸimu provozovat zaĆĂzenĂ, kterĂĄ komunikujĂ primĂĄrnÄ pomocĂ automatizaÄnĂho protokolu (zejmĂ©na tedy PLC, integraÄnĂ regulĂĄtory, aplikaÄnĂ brĂĄny apod.). TakovĂĄ zaĆĂzenĂ jsou obvykle vybavena fyzickĂœmi vstupy a vĂœstupy nebo jsou k nim pĆipojena dalĆĄĂ zaĆĂzenĂ napĆ. pomocĂ linky RS485. Vzhledem k tomu, ĆŸe tato zaĆĂzenĂ nejsou klĂÄovĂœmi prvky systĂ©mu, postaÄuje vĆĄak ÄasnĂĄ detekce zĂĄvady a jejĂ oprava.
Pokud se rozhodneme pro zavĂĄdÄnĂ redundantnĂch prvkĆŻ v BMS, je tĆeba si uvÄdomit, ĆŸe tato ĆeĆĄenĂ vĆŸdy pĆinĂĄĆĄejĂ zvĂœĆĄenĂ© nĂĄroky na sprĂĄvu systĂ©mu. DĂky komplikovanosti vyuĆŸĂvanĂœch technologiĂ mĆŻĆŸe i drobnĂĄ nekonzistence nebo chyba v nastavenĂ zpĆŻsobit zhroucenĂ celĂ©ho systĂ©mu. KromÄ sprĂĄvnĂ© konfigurace je tĆeba zajistit i konzistenci dat a programovĂ©ho vybavenĂ na redundantnĂch prvcĂch. Jako pĆĂklad poslouĆŸĂ provozovĂĄnĂ vizualizaÄnĂch serverĆŻ BMS v reĆŸimu rozloĆŸenĂ zĂĄtÄĆŸe. V pĆĂpadÄ, ĆŸe se na vĆĄech serverech nenachĂĄzĂ stejnĂ© verze dat (vizualizaÄnĂch „obrazovek“) nebo jsou vybaveny rozdĂlnĂœmi verzemi softwaru, z vnÄjĆĄĂho pohledu se systĂ©m chovĂĄ naprosto nevypoÄitatelnÄ a nahodile uĆŸivateli zobrazuje rĆŻznĂĄ data podle toho, na kterĂœ z uzlĆŻ je uĆŸivatel zrovna pĆipojen. Tyto problĂ©my je velice obtĂĆŸnĂ© diagnostikovat a lze jim pĆedchĂĄzet buÄ dĆŻslednĂœm dodrĆŸovĂĄnĂm pracovnĂch postupĆŻ pĆi ĂșpravĂĄch systĂ©mu, nebo pomocĂ technickĂœch ĆeĆĄenĂ jako automatickĂĄ synchronizace dat mezi uzly (napĆ. DFS Replication – Distributed File System Replication v MS Windows Server).
V pĆĂpadÄ vĂœpadku nÄkterĂ©ho z redundantnĂch prvkĆŻ systĂ©mu jsou moĆŸnĂ© dva zĂĄkladnĂ scĂ©nĂĄĆe. BuÄ pouĆŸitĂĄ technologie sama detekuje zĂĄvadu, nefunkÄnĂ prvek vyĆadĂ z provozu a adaptuje se automaticky na novou situaci, nebo chyba nenĂ detekovatelnĂĄ vestavÄnĂœmi mechanismy a je tĆeba zmÄnu konfigurace vynutit zvenÄĂ, aĆ„ uĆŸ automatizovanÄ, nebo ruÄnĂm zĂĄsahem. ObecnÄ platĂ, ĆŸe technologie pro zajiĆĄtÄnĂ redundance jsou schopnĂ© reagovat na zĂĄvaĆŸnĂ© (a tudĂĆŸ snadno rozpoznatelnĂ©) problĂ©my, jako je napĆĂklad selhĂĄnĂ hardwaru nebo vĂœpadek napĂĄjenĂ, mĂ©nÄ kritickĂ© problĂ©my (ztrĂĄta sĂĆ„ovĂ©ho spojenĂ, pĂĄd aplikace, chybnĂĄ konfigurace) vĆĄak zĆŻstĂĄvajĂ nepovĆĄimnuty. V nĂĄsledujĂcĂch dvou ÄĂĄstech se tedy vÄnujeme zpĆŻsobĆŻm, jak takovĂ© zĂĄvady detekovat a jak na nÄ reagovat.
Dohledové systémy
AutomatizovanĂ© dohledovĂ© systĂ©my nad BMS slouĆŸĂ k vÄasnĂ© detekci zĂĄvad. DohledovĂœ systĂ©m se uplatnĂ jak u kritickĂœch zĂĄvad, kde je tĆeba zajistit co nejniĆŸĆĄĂ dobu odezvy a opravy, tak u skrytĂœch zĂĄvad, kterĂ© jinak mohou v systĂ©mu zĆŻstat neodhaleny po dlouhou dobu, zpÄtnÄ vĆĄak mohou zpĆŻsobovat problĂ©my. BMS sĂĄm o sobÄ sice obsahuje mechanismy pro detekci zĂĄvad (alarmovĂ© zprĂĄvy a notifikace), tyto vestavÄnĂ© metody vĆĄak jsou vhodnĂ© spĂĆĄe pro odhalovĂĄnĂ problĂ©mĆŻ podĆĂzenĂœch zaĆĂzenĂ (napĆ. technologie HVAC). V pĆĂpadÄ chyby v samotnĂ©m BMS nebo automatizaÄnĂm systĂ©mu mĆŻĆŸe bĂœt vestavÄnĂœ detekÄnĂ mechanismus takĂ© nefunkÄnĂ. Pro takovĂ© pĆĂpady je moĆŸnĂ© pouĆŸĂt dodateÄnĂ© dohledovĂ© systĂ©my, kterĂ© sledujĂ samotnou funkcionalitu BMS (napĆ. prĂĄvÄ sprĂĄvnou funkci vizualizaÄnĂho serveru, archivnĂho serveru nebo sledovĂĄnĂ dostupnosti jednotlivĂœch zaĆĂzenĂ v BMS).
DohledovĂ© systĂ©my lze v oblasti BMS rozdÄlit do tĆĂ kategoriĂ podle toho, na kterou ĂșroveĆ BMS se zamÄĆujĂ:
- StandardnĂ ICT systĂ©my – SledujĂ systĂ©m na Ășrovni sĂĆ„ovĂ© infrastruktury. Tyto systĂ©my sledujĂ sĂĆ„ovou dostupnost a provoznĂ parametry aktivnĂch prvkĆŻ poÄĂtaÄovĂ© sĂtÄ (pĆepĂnaÄe, smÄrovaÄe, servery, UPS jednotky s komunikaÄnĂm rozhranĂm). Pro detekci zĂĄvad vyuĆŸĂvajĂ zejmĂ©na standardizovanĂ© a rozĆĄĂĆenĂ© protokoly ICMP a SNMP. Tyto nĂĄstroje nelze vyuĆŸĂt napĆ. pro specializovanĂĄ automatizaÄnĂ zaĆĂzenĂ (PLC), kterĂĄ tyto protokoly nepodporujĂ, nebo pro detekci chyb v pouĆŸĂvanĂ©m softwarovĂ©m vybavenĂ;
- ĂroveĆ automatizaÄnĂho protokolu – Tento dohledovĂœ systĂ©m komunikuje se specializovanĂœmi zaĆĂzenĂmi, implementujĂcĂmi specifickĂœ automatizaÄnĂ protokol jako napĆĂklad BACnet v pĆĂpadÄ Masarykovy univerzity. UmoĆŸĆuje sledovat dostupnost klĂÄovĂœch zaĆĂzenĂ BMS a jejich provoznĂ parametry, napĆĂklad nastavenĂ Äasu, hodnoty vĂœznamnĂœch promÄnnĂœch nebo vstupĆŻ a podobnÄ;
- AplikaÄnĂ ĂșroveĆ – Z dĆŻvodu spolehlivosti nebo efektivity mĆŻĆŸe bĂœt nejvhodnÄjĆĄĂm ĆeĆĄenĂm pro detekci chyb na Ășrovni softwaru vyuĆŸĂt na mĂru vytvoĆenĂĄ ĆeĆĄenĂ, kterĂĄ sice nevyuĆŸĂvajĂ standardizovanĂœch protokolĆŻ, jsou vĆĄak schopnĂĄ detekovat i jinak jen tÄĆŸko odhalitelnĂ© zĂĄvady. Tyto detekÄnĂ mechanismy vyuĆŸĂvajĂ technik jako automatickĂĄ analĂœza databĂĄze aplikace (archivnĂho serveru) Äi aplikaÄnĂho archivu udĂĄlostĂ („logu“) nebo simulace akcĂ uĆŸivatele vizualizaÄnĂ aplikace BMS.
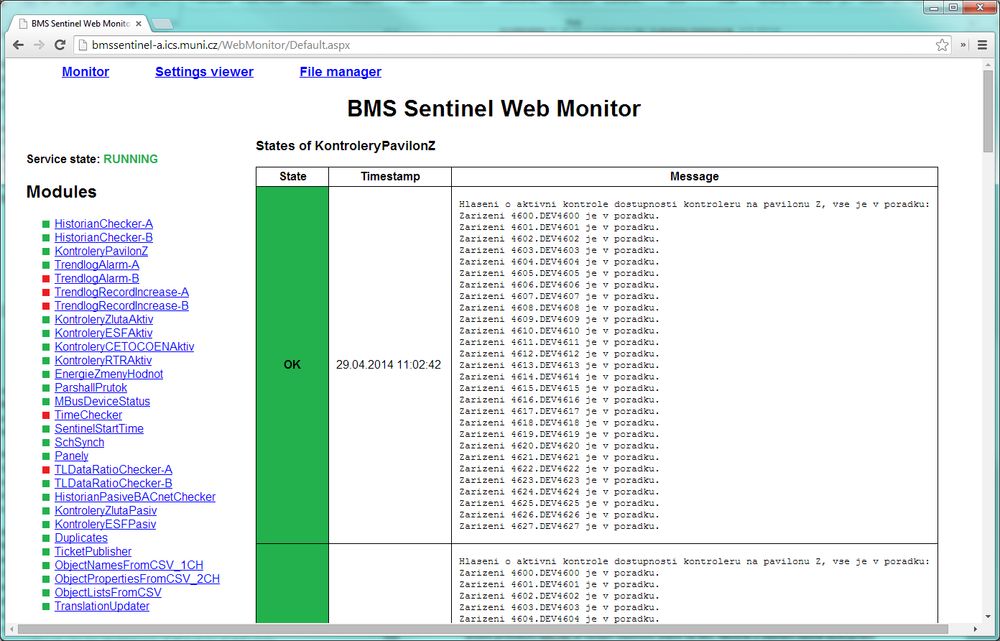
ObrĂĄzek 2: DohledovĂœ systĂ©m pro BACnet
Na MasarykovÄ univerzitÄ jsou pouĆŸĂvĂĄny dohledovĂ© systĂ©my na vĆĄech uvedenĂœch ĂșrovnĂch. Dohled nad ICT infrastrukturou je zajiĆĄĆ„ovĂĄn pomocĂ Open Source nĂĄstroje Nagios. DohledovĂœ systĂ©m na Ășrovni protokolu BACnet je vyvĂjen vlastnĂmi silami na MU. NevĂme o ĆŸĂĄdnĂ©m bÄĆŸnÄ dostupnĂ©m ĆeĆĄenĂ, kterĂ© by takovouto funkcionalitu zajiĆĄĆ„ovalo. DohledovĂœ systĂ©m je vybaven uĆŸivatelskĂœm rozhranĂm v podobÄ jednoduchĂ© webovĂ© aplikace (viz ObrĂĄzek 2: DohledovĂœ systĂ©m pro BACnet). ZĂĄroveĆ umoĆŸĆuje i notifikaci uĆŸivatelĆŻ na zjiĆĄtÄnĂ© zĂĄvady pomocĂ e-mailu a je moĆŸnĂ© propagovat zprĂĄvy do systĂ©mu Nagios, kterĂœ je sledovĂĄn dohledovĂœm centrem pro sĂĆ„ovou infrastrukturu na MU. OperĂĄtoĆi dohledovĂ©ho centra potĂ© mohou zpracovĂĄvat hlĂĄĆĄenĂ chyb ze systĂ©mu BMS stejnÄ jako ostatnĂ poruchy a smÄrovat je na zodpovÄdnĂ© pracovnĂky.
DohledovĂ© systĂ©my obecnÄ v pĆĂpadÄ odhalenĂ© zĂĄvady pouze upozornĂ na existenci problĂ©mu, protoĆŸe nĂĄprava situace obvykle nebĂœvĂĄ natolik triviĂĄlnĂ, aby ĆĄla automatizovat. V nÄkterĂœch situacĂch lze vĆĄak vyuĆŸĂt vĂœhod redundantnĂ infrastruktury a problĂ©m provizornÄ vyĆeĆĄit odstavenĂm vyĆazenĂ©ho prvku. Tento postup je moĆŸnĂ© ilustrovat na pĆĂkladu vĂce uzlĆŻ vizualizaÄnĂho rozhranĂ BMS, provozovanĂœch v reĆŸimu Network Load Balancing. V pĆĂpadÄ, ĆŸe dohledovĂœ systĂ©m detekuje zĂĄvadu na jednom z uzlĆŻ, mĆŻĆŸe se nejdĆĂve pokusit o restart uzlu. Pokud tento postup nevede k odstranÄnĂ zĂĄvady, mĆŻĆŸe dohledovĂœ systĂ©m autonomnÄ rozhodnout o doÄasnĂ©m vyĆazenĂ uzlu z clusteru a odeslĂĄnĂ zprĂĄvy sprĂĄvci systĂ©mu.
Reakce na zĂĄvadu a znalostnĂ databĂĄze
Ve chvĂli, kdy dojde k detekci zĂĄvady, aĆ„ uĆŸ tak, ĆŸe ji nahlĂĄsĂ uĆŸivatel, nebo byla odhalena automatizovanĂœmi systĂ©my, je tĆeba na ni zareagovat takovĂœm zpĆŻsobem a v takovĂ©m Äase, aby ovlivnila provoz systĂ©mu v co nejmenĆĄĂ moĆŸnĂ© mĂĆe. KlĂÄem k efektivnĂmu ĆeĆĄenĂ problĂ©mĆŻ je definice jasnĂœch postupĆŻ, pokrĂœvajĂcĂch jak samotnĂ© hlĂĄĆĄenĂ zĂĄvady, tak jejĂ odstranÄnĂ.
ObecnÄ je tĆeba minimalizovat zĂĄvislost systĂ©mu na dostupnosti jednoho konkrĂ©tnĂho pracovnĂka, kterĂœ pĆijĂmĂĄ zprĂĄvy o zĂĄvadĂĄch, nebo kterĂœ umĂ zĂĄvadu odstranit. ZĂĄroveĆ je ale tĆeba jasnÄ stanovit, kdo zodpovĂdĂĄ za odstranÄnĂ objevenĂ© zĂĄvady, aby nedochĂĄzelo k situacĂm, kdy zĂĄvadu neĆeĆĄĂ nikdo, nebo naopak zbyteÄnÄ nÄkolik lidĂ nezĂĄvisle na sobÄ.
Proto je vhodnĂ© zĆĂdit jedno kontaktnĂ mĂsto (tzv. Helpdesk) pro hlĂĄĆĄenĂ zĂĄvad s vyĆĄkolenĂœmi pracovnĂky, kteĆĂ budou schopni zĂĄvadu buÄ sami odstranit, nebo pĆedat pĆĂsluĆĄnĂ©mu specialistovi. IdeĂĄlnĂ situace pak nastĂĄvĂĄ tehdy, kdyĆŸ sprĂĄvci systĂ©mu vyuĆŸĂvajĂ vhodnĂœ systĂ©m pro evidenci poĆŸadavkĆŻ, kde je moĆŸnĂ© Ășkoly pĆiĆazovat konkrĂ©tnĂm lidem a evidovat jejich dokonÄenĂ. Na zĂĄkladÄ tÄchto dat je pak moĆŸnĂ© zpÄtnÄ vyhodnocovat napĆ. doby odezvy a dalĆĄĂ provoznĂ data. Oblast hlĂĄĆĄenĂ zĂĄvad a pravidelnĂ© i vyĆŸĂĄdanĂ© ĂșdrĆŸby vÄetnÄ pĆidruĆŸenĂ© analytiky bĂœvĂĄ pokryta v systĂ©mech pro podporu facility managementu (CAFM – Computer Aided Facility Management).
Pro pĆĂpady opakujĂcĂch se provoznĂch problĂ©mĆŻ je vhodnĂ© mĂt k dispozici znalostnĂ databĂĄzi, kterĂĄ obsahuje pĆesnÄ definovanĂ© postupy pro odstranÄnĂ zĂĄvady nebo alespoĆ minimalizaci jejĂch nĂĄsledkĆŻ do doby, neĆŸ bude plnÄ opravena (napĆ. postupy pro vyĆazenĂ nefunkÄnĂch prvkĆŻ systĂ©mu, kterĂ© mohou bĂœt nahrazeny v rĂĄmci redundantnĂ infrastruktury). Na zĂĄkladÄ tÄchto postupĆŻ mohou nÄkterĂ© Ășkony provĂĄdÄt i nespecializovanĂ pracovnĂci, coĆŸ vĂœznamnÄ sniĆŸuje dobu reakce na zĂĄvadu.
SprĂĄva konfiguracĂ a sklad nĂĄhradnĂch dĂlĆŻ
VelkĂ© mnoĆŸstvĂ zĂĄvad bĂœvĂĄ zpĆŻsobeno nevhodnou zmÄnou konfigurace nÄkterĂ©ho prvku systĂ©mu nebo jeho ĂșplnĂœm zniÄenĂm. V obou pĆĂpadech je nejsnazĆĄĂ a nejrychlejĆĄĂ cestou k obnovenĂ funkÄnosti systĂ©mu jeho uvedenĂ do pĆŻvodnĂho stavu tĂm, ĆŸe pouĆŸijeme poslednĂ znĂĄmou funkÄnĂ konfiguraci.
Pokud se jednĂĄ pouze o problĂ©m konfigurace, lze pouĆŸĂt stĂĄvajĂcĂ zaĆĂzenĂ. Pokud je chyba na Ășrovni hardwaru, je tĆeba mĂt k dispozici nĂĄhradnĂ zaĆĂzenĂ a funkÄnĂ konfiguraci aplikovat na nÄj. V obou situacĂch je nutnĂ© mĂt k dispozici zĂĄlohu poslednĂ funkÄnĂ konfigurace, protoĆŸe opravenĂ chyby nebo kompletnĂ definice novĂ© konfigurace mohou bĂœt zdlouhavĂ©.
Z toho dĆŻvodu by bylo vhodnĂ© mĂt k dispozici pravidelnÄ (nejlĂ©pe automaticky) poĆizovanĂ© zĂĄlohy konfigurace vĆĄech prvkĆŻ systĂ©mu, kterĂ© by bylo moĆŸnĂ© pouĆŸĂt pro obnovu, to je vĆĄak bohuĆŸel v mnoha pĆĂpadech nemoĆŸnĂ©. Toto je jedna z oblastĂ, kterĂĄ je dobĆe oĆĄetĆena v oblasti sprĂĄvy poÄĂtaÄovĂœch sĂtĂ, pro oblast automatizace budov vĆĄak je (alespoĆ v prostĆedĂ Masarykovy univerzity) udrĆŸovĂĄnĂ aktuĂĄlnĂch zĂĄloh obtĂĆŸnÄ realizovatelnĂ©. To je zpĆŻsobeno zejmĂ©na tĂm, ĆŸe napĆ. pro protokol BACnet neexistuje standardizovanĂœ zpĆŻsob zĂĄlohovĂĄnĂ, kterĂœ by navĂc vĂœrobci byli nuceni implementovat. Ve vĂœsledku tak kaĆŸdĂœ z vĂœrobcĆŻ automatizaÄnĂch zaĆĂzenĂ nabĂzĂ vlastnĂ ĆeĆĄenĂ pro zĂĄlohovĂĄnĂ konfigurace, kterĂ© jsou vzĂĄjemnÄ nekompatibilnĂ a Äasto navĂc ani neumoĆŸĆujĂ automatizaci.
V pĆĂpadÄ vĂœpadku nÄkterĂ© komponenty systĂ©mu, kterĂĄ nenĂ provozovĂĄna v redundantnĂm reĆŸimu (typicky tedy regulĂĄtoru) je pro rychlĂ© obnovenĂ provozu navĂc vhodnĂ© mĂt zĆĂzenĂœ sklad nĂĄhradnĂch dĂlĆŻ a zaĆĂzenĂ. Je samozĆejmÄ nereĂĄlnĂ© drĆŸet nĂĄhradnĂ zaĆĂzenĂ od vĆĄech pouĆŸitĂœch zaĆĂzenĂ, proto je tĆeba peÄlivÄ definovat ty ÄĂĄsti systĂ©mu, pro kterĂ© je to pravdu nutnĂ©, a poÄet kusĆŻ, kterĂ© je pro tyto ĂșÄely tĆeba drĆŸet. Jako vodĂtko mohou sloĆŸit zejmĂ©na cena zaĆĂzenĂ, poÄet nasazenĂœch kusĆŻ a akceptovatelnĂĄ doba vĂœpadku.
Auditing a sprĂĄva uĆŸivatelskĂœch oprĂĄvnÄnĂ
DalĆĄĂm krokem po odstranÄnĂ zĂĄvady je zjiĆĄtÄnĂ jejĂ pĆĂÄiny, aby bylo moĆŸnĂ© v budoucnu moĆŸnĂ© zĂĄvadÄ pĆedejĂt. Z toho dĆŻvodu by bylo ideĂĄlnĂ mĂt k dispozici audit (denĂk) veĆĄkerĂœch zĂĄsahĆŻ do systĂ©mu. Tento seznam zĂĄsahĆŻ je bohuĆŸel nutnĂ© z velkĂ© ÄĂĄsti udrĆŸovat ruÄnÄ, v tom pĆĂpadÄ vĆĄak nikdy nelze zĂskat zĂĄruku, ĆŸe je denĂk ĂșplnĂœ. AutomatizovanĂ© poĆizovĂĄnĂ denĂku je vĆĄak v mnoha pĆĂpadech nemoĆŸnĂ©, napĆĂklad kdyĆŸ dochĂĄzĂ k vĂœmÄnÄ hardwaru. StejnÄ jako v oblasti odstraĆovĂĄnĂ zĂĄvad, i zde mĆŻĆŸe dobĆe poslouĆŸit CAFM systĂ©m, poskytujĂcĂ podporu pro evidenci poĆŸadavkĆŻ a provĂĄdÄnĂœch pracovnĂch ĂșkonĆŻ.
Naopak nenĂ problĂ©m v BMS sledovat veĆĄkerĂ© bÄĆŸnĂ© uĆŸivatelskĂ© akce, jako napĆĂklad ovlĂĄdĂĄnĂ provozu budovy pĆes vizualizaÄnĂ rozhranĂ BMS, kterĂ© mohou pĆi zjiĆĄĆ„ovĂĄnĂ pĆĂÄin zĂĄvad taktĂ©ĆŸ uĆŸiteÄnĂ©. VyuĆŸĂvĂĄnĂ vizualizaÄnĂho rozhranĂ BMS v reĆŸimu klient-server umoĆŸĆuje takĂ© centralizovanou sprĂĄvu uĆŸivatelskĂœch skupin a oprĂĄvnÄnĂ, coĆŸ dĂĄle sniĆŸuje riziko nekvalifikovanĂœch zĂĄsahĆŻ do systĂ©mu. V pĆĂpadÄ, kdy je kaĆŸdĂœ uĆŸivatel vybaven vlastnĂm pĆipojenĂm do BMS a vlastnĂ plnohodnotnou aplikacĂ pro prĂĄci s BMS, je sprĂĄva uĆŸivatelskĂœch oprĂĄvnÄnĂ a evidence zĂĄsahĆŻ do systĂ©mu vĂœraznÄ sloĆŸitÄjĆĄĂ, neĆŸ kdyĆŸ uĆŸivatelĂ© do BMS pĆistupujĂ pĆes jeden „vstupnĂ bod“ – vizualizaÄnĂ server.
Ăpravy systĂ©mu
KritickĂœm obdobĂm pro zajiĆĄtÄnĂ nepĆetrĆŸitĂ© funkÄnosti BMS jsou zejmĂ©na chvĂle, kdy dochĂĄzĂ k rozĆĄiĆovĂĄnĂ systĂ©mu (napĆ. kdyĆŸ je pĆipojovĂĄna novĂĄ budova). ZkuĆĄenosti ukazujĂ, ĆŸe automatizaÄnĂ zaĆĂzenĂ i softwarovĂ© aplikace bĂœvajĂ nĂĄchylnĂ© na mnoĆŸstvĂ komunikace v sĂti a pĆi zahlcenĂ nefungujĂ sprĂĄvnÄ. PĆi pĆipojenĂ novĂ©ho zaĆĂzenĂ se mĆŻĆŸe snadno stĂĄt, ĆŸe konfigurace nenĂ pĆizpĆŻsobena stĂĄvajĂcĂmu systĂ©mu, nebo je dokonce zaĆĂzenĂ neschopnĂ© v BMS bez problĂ©mĆŻ fungovat. V obou pĆĂpadech mĆŻĆŸe dojĂt k tomu, ĆŸe je sĂĆ„ zahlcena velkĂœm mnoĆŸstvĂm nesmyslnĂœch zprĂĄv a mĆŻĆŸe dochĂĄzet k vĂœpadkĆŻm celĂ©ho BMS.
TÄmto situacĂm je naĆĄtÄstĂ moĆŸnĂ© pĆedchĂĄzet. Pro otestovĂĄnĂ novĂ©ho typu zaĆĂzenĂ je vhodnĂ© nejdĆĂve ho pĆipojit do oddÄlenĂ© testovacĂ sĂtÄ, kterĂĄ vĆĄak obsahuje zĂĄkladnĂ komponenty BMS, jako napĆĂklad vizualizaÄnĂ a archivnĂ server a v menĆĄĂm mÄĆĂtku kopĂruje strukturu BMS. Pro snĂĆŸenĂ nĂĄkladĆŻ lze napĆĂklad pouĆŸĂt vĂœvojĂĄĆskĂ© verze aplikacĂ nebo varianty s minimĂĄlnĂm poÄtem licencĂ pro datovĂ© body. V tomto prostĆedĂ mĆŻĆŸe dojĂt ke zprovoznÄnĂ zaĆĂzenĂ, prozkoumĂĄnĂ moĆŸnostĂ konfigurace a zejmĂ©na k ovÄĆenĂ, jestli zaĆĂzenĂ dostateÄnÄ podporuje vĆĄechny sluĆŸby, kterĂ© jsou vyĆŸadovĂĄny v danĂ©m BMS (uklĂĄdĂĄnĂ archivnĂch dat, odesĂlĂĄnĂ alarmĆŻ a notifikacĂ, synchronizace Äasu, korektnĂ vizualizace dat ze zaĆĂzenĂ v uĆŸivatelskĂ©m rozhranĂ, atd.).
V zĂĄjmu dĆŻkladnĂ©ho provÄĆenĂ schopnostĂ zaĆĂzenĂ je vhodnĂ© vypracovat metodiku testovĂĄnĂ – „testovacĂ proceduru“, kterĂĄ se postupnÄ zamÄĆuje na vĆĄechny aspekty provozu. Po ovÄĆenĂ kompatibility zaĆĂzenĂ lze s vysokou jistotou tvrdit, ĆŸe jeho nasazenĂ do BMS nepĆinese problĂ©my.
Pro ovÄĆenĂ funkÄnosti vÄtĆĄĂch celkĆŻ (novĂ© budovy nebo areĂĄlu) je moĆŸnĂ© vyuĆŸĂt provoz v tzv. „ostrovnĂm reĆŸimu“. V tomto pĆĂpadÄ je systĂ©m plnÄ nakonfigurovanĂœ a funkÄnĂ vÄetnÄ nĂĄvaznostĂ na podĆĂzenĂ© systĂ©my, jsou vytvoĆeny novĂ© podklady pro uĆŸivatelskĂ© rozhranĂ, lokĂĄlnĂ sĂĆ„ je dovybavena archivnĂm a vizualizaÄnĂm serverem a systĂ©m je provozovĂĄn stejnÄ, jako tomu bude pozdÄji v ostrĂ©m provozu. OstrovnĂ reĆŸim tak umoĆŸĆuje odstranit rĆŻznĂ© problĂ©my v konfiguraci jeĆĄtÄ bÄhem testovacĂho provozu a poskytuje Äas pro Ășpravy konfiguracĂ tak, aby byly kompatibilnĂ se stĂĄvajĂcĂm prostĆedĂm. Je tak moĆŸnĂ© vyhnout se znaÄnĂœm problĂ©mĆŻm, kterĂ© by mohly nastat pĆi pĆipojovĂĄnĂ rovnou do stĂĄvajĂcĂho systĂ©mu.
ZĂĄvÄr
CĂlem tohoto ÄlĂĄnku bylo pĆedstavit rĆŻznĂ© metody pro zajiĆĄtÄnĂ spolehlivosti a vysokĂ© dostupnosti aplikacĂ a komponent BMS. SpolehlivĂœ chod tohoto systĂ©mu se stĂĄvĂĄ klĂÄovĂœm v rozsĂĄhlĂœch instalacĂch, kde se jednĂĄ o jedinou efektivnĂ cestu pro spravovĂĄnĂ automatizaÄnĂch technologiĂ budov. Podle zkuĆĄenostĂ z dlouhodobĂ©ho provozu BMS na MasarykovÄ UniverzitÄ se ukazuje, ĆŸe pĆedstavenĂ© aspekty hrajĂ klĂÄovou roli pĆi zajiĆĄĆ„ovĂĄnĂ bezproblĂ©movĂ©ho provozu.
I relativnÄ velkĂœ BMS samozĆejmÄ mĆŻĆŸe uspokojivÄ fungovat bez tÄchto nĂĄstrojĆŻ, uvedenĂ© postupy vĆĄak mohou vĂœraznÄ zvĂœĆĄit kvalitu sluĆŸby zejmĂ©na v kritickĂœch situacĂch, kterĂœm se bohuĆŸel nenĂ moĆŸnĂ© zcela vyhnout (napĆ. selhĂĄnĂ hardwaru). TypickĂœ scĂ©nĂĄĆ pravdÄpodobnÄ vypadĂĄ tak, ĆŸe techniky pro zajiĆĄtÄnĂ vysokĂ© dostupnosti a spolehlivosti systĂ©mu jsou zavĂĄdÄny postupnÄ v prĆŻbÄhu provozu jako reakce na havĂĄrie. To je i pĆĂpad Masarykovy univerzity. Technicky tento postup nepĆedstavuje problĂ©m, zejmĂ©na zavĂĄdÄnĂ novĂœch metod prĂĄce a souvisejĂcĂch kontrolnĂch procesĆŻ vĆĄak je nĂĄroÄnĂ© z organizaÄnĂho hlediska, je totiĆŸ nutnĂ© zmÄnit zabÄhnutĂ© postupy a nahradit je novĂœmi (a obvykle zdlouhavÄjĆĄĂmi), coĆŸ se pochopitelnÄ nesetkĂĄvĂĄ s nadĆĄenĂm.
NastĂnÄnĂĄ ĆeĆĄenĂ bezpochyby pĆinĂĄĆĄĂ zvĂœĆĄenĂ© finanÄnĂ nĂĄroky (zejmĂ©na kvĆŻli nĂĄkupu hardwaru pro zajiĆĄtÄnĂ redundance infrastruktury a drĆŸenĂ skladu nĂĄhradnĂch dĂlĆŻ), od urÄitĂ© velikosti systĂ©mu vĆĄak nepĆedstavujĂ pĆĂliĆĄ velkĂœ relativnĂ nĂĄrĆŻst ceny. ÄĂm vÄtĆĄĂ systĂ©m je, tĂm vĂce pravdÄpodobnÄ roste i jeho dĆŻleĆŸitost, dĂĄ se tedy ĆĂct, ĆŸe v urÄitĂœch situacĂch jsou tyto investice prakticky nevyhnutelnĂ©.
Modern buildings allow to unify monitoring and controlling of building automation and electronic systems under a common environment known as a Building Management System. Although in many environments the BMS represents an unnecessary feature that only improves the user experience, with growing size of the facility the BMS becomes essential for a building operation. BMS ensures a communication between users and devices and helps to significantly reduce costs of a system expansion. In that case, a reliability and an availability of the BMS becomes critical for a smooth operation. This article presents technical, methodical and process aspects of a high reliability in the BMS, based on experience with a long-term operation of the BMS at the Masaryk University. Fulfilling the presented principles enables the BMS to serve as a primary environment for controlling of the building operation.